2.4.1 The Equations of Evolution
These chapters propose a model of evolution slightly different from the standard theory. Fitness is directional, and change incurs cost. Even so, the standard theory can now model evolution precisely, by equations, and these equations show that there is no cost or directionality to change. So, if somebody proposes that these effects occur, that person needs to explain how such effects would appear in equations.
Needless to say, this is very difficult. The topic is highly specialized, plus much of the subject concerns how diploid alleles will distribute in a mostly stable population. The equations are variations to the equality;
(p + q)2 = p2 + q2 +2pq (The Hardy-Weinberg Equation)
The problem is that diploid organisms in a stable population represent an already highly directional form of change. (The direction is towards the wealth of allele variety.) Yet, the first 2-3 billion years of life were haploid, or even among diploid species, 70-90% of loci are homozygous (with little allele variety). So, although it is often derived from a Hardy-Weinberg equation, broader evolution can better analyzed via a so-called Fisher/Wright model (after R. A. Fisher and Sewall Wright).
A very simple Fisher/Wright model can be shown here. Suppose an individual has a locus X on a chromosome, which can be occupied by a range of genes or alleles xi, where i = 1, 2, 3... (xi means the distribution value, so 1 in 100 is 0.01. Here it also refers to the gene 'xi'.) If each variation of xi has a fitness wi, the population has a mean fitness ![]() (w bar) of S wixi about X. R. A. Fisher showed that if wi of any gene xi was greater than the mean,
(w bar) of S wixi about X. R. A. Fisher showed that if wi of any gene xi was greater than the mean, ![]() , rate of spread D xi of xi in a natural population (for a haploid, at t= 0) would be;
, rate of spread D xi of xi in a natural population (for a haploid, at t= 0) would be;
D
xi = xi (wi -This shows that the fitter wi makes an individual above![]() , the greater is wi -
, the greater is wi - ![]() , so the faster xi spreads until
, so the faster xi spreads until ![]() rises to wi.
rises to wi.
For example, suppose a mosquito population has 1,000 individuals. One individual has an allele, x2, resistant to DDT (w2 =1) and the other 999 x1 individuals have only 50% resistance (w1 = 0.5) With no DDT, each generation (wi - ![]() ) = 0, so x2 does not increase (D x2 = 0). But once DDT is present, x1 halves each generation, while x2 quickly increases its frequency from x2 = 0.001 to x2 = 1.0 by about the 18th generation. So although favorable mutations may be small, they can spread very fast. And the spread can be traced by the history, or frequency, of the allele or gene causing the change. This principle is so central that Fisher called it the fundamental theorem of natural selection.
) = 0, so x2 does not increase (D x2 = 0). But once DDT is present, x1 halves each generation, while x2 quickly increases its frequency from x2 = 0.001 to x2 = 1.0 by about the 18th generation. So although favorable mutations may be small, they can spread very fast. And the spread can be traced by the history, or frequency, of the allele or gene causing the change. This principle is so central that Fisher called it the fundamental theorem of natural selection.
However, by 'mean fitness' ![]() , Fisher's theorem refers to the mean about a single locus X. But genomes contain many loci, X, Y, Z. If we take a different mean fitness over all genome loci X, Y, Z... as wG, then most equations (not just Fisher's one) rely on a condition wG = wi. This assumption simplifies calculations by replacing fitness of the thousands of genes in the genome, wG, by the fitness of just the one gene or allele, wi, causing the change. Even so, assumption wG = wi "throws away the organism", so we need to understand which role exactly the organism does play, in how genes spread.
, Fisher's theorem refers to the mean about a single locus X. But genomes contain many loci, X, Y, Z. If we take a different mean fitness over all genome loci X, Y, Z... as wG, then most equations (not just Fisher's one) rely on a condition wG = wi. This assumption simplifies calculations by replacing fitness of the thousands of genes in the genome, wG, by the fitness of just the one gene or allele, wi, causing the change. Even so, assumption wG = wi "throws away the organism", so we need to understand which role exactly the organism does play, in how genes spread.
2.4.2 Gene Trajectory
Earlier, Section 2.2.3 introduced the concept of gene trajectory. As explained, physically there are many reasons why genes alter or mutate at different rates over the history of life. But whatever the physical cause, we might liken fidelity of copy of a gene or DNA sequence to a force, call it e i (eta i). If say, a gene did not alter copy by even 1 bp for eternity, then e i = ¥ . If a gene could alter each reproduction, then e i = 0. No gene can obtain these extremes (life has not existed for eternity) so we assume that there is an average e (eta bar) for all genes, that can be normalized such that e = 1, for any typical gene.
The concept of e i, allows us to investigate the assumption wG = wi. Basically, when gene xi increases its frequency, say 0.1® 0.9, it does so in a certain "direction", in which every gene in the host genome, G, also increases frequency, say 0.1® 0.9, by the same amount. So it seems safe to set wG = wi, because for any selective event every gene in G alters its frequency by the same amount anyway. However, the value of e i, if it exist, will be very different for each gene in the genome. And while xi in small populations alters rapidly, e i alters slowly over the history of life, and is unlikely to be affected by small changes.
In fact, while it is not the same, e i can be derived from mutation rate m i (mu i). To be sure, m i, is a scalar. It measures statistical change in the present time, such as the rate by which an allele x1® x2 mutates to enter the gene pool of a modern population. On the other hand, e i is a vector. It is the retentive force that holds a gene within a copy trajectory, over the history of life. Genes also mutate for many reasons. Instability at a single region of a gene could cause high m i, but low e i if the rest of the gene was stable. Or an opportunistic gene can have low e i, but medium m i. Still, data for m i is available. If average normalized e is a function of average mutation rate, m (mu bar) such that;
e
= f(m ) = 1, then for any gene mutating at rate m i, approximately;e
i = 7Ö (m /m i)Having broadly defined e i, we can show its relationship to xi as a complex sum. Take distribution Di of a gene xi as Di = xi. This becomes Di = xi(1 + je i) where j = Ö -1. But because 0 < e i < ¥ , this needs to be normalized to keep Di £ 1, so the full expression becomes;
Di = xi(1 + je i)/Ö (e i2 + 1)
It looks complicated, but notice that the value of e i does not alter the value of Di as xi, but only varies its complex sign. (If e i = 0, Di = xi. Yet if e i = ¥ , Di = jxi.) It is harder to show, but if e i was the same for all genes then again Di = xi. (If for two alleles D1 = kD2, if e 1 = e 2, then x1 = kx2.) So, the new notation is not that different from standard theory. If e i = 0, is the same for all genes, or has no effect, standard theory is conserved. Just that if e i does exist, or is not the same for all genes, we can now examine what is lost when we set wG = wi.
2.4.3 The Use of Angle Notation
The affects of change in a genome, where different forces of e i act on different genes, can be best visualized using an angle notation. When people are told that there is an angle, they expect to see a physical angle, like angles forming the DNA helix. However, the term (1 + je i)/Ö (e i2 + 1) is also an angle, where q i = tan-1 (e i). So;
Di = xi (1 + je i)/Ö (e i2 + 1) is the equivalent of;
Di = xi (cos q i + j sin q i) or, Di = (xi, q i)
Further, for any value of e i, broadly;
e
i = ¥ , m i » 0 ("forever"), q i = 90Oe
i = 1, m i » m ("average"), q i = 45Oe
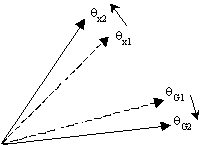
i = 0, m i » 1 ("each reproduction"), q i = 0OThis is shown in Fig. 2.4.1. There is no physical angle, but the notation helps visualize how genes, genomes and DNA segments interact over the history of life. Highly conserved genes barely alter over huge times, so they are at high angles. Because evolution is adaptation to change, genes will only be able to stay unaltered while adapting into a huge variety of types if other DNA in the genome bears the cost of change. This will appear on the diagram as though, over time, conserved genes 'rotate' higher, but genomes 'rotate' to lower angles.
|
|
Fig 2.4.1 Genes, DNA, and genomes appear to spread together in single organisms. But over the history of life, individual genes try to avoid altering sequence, by forcing host genomes to bear the cost of change. On an angle diagram, it would appear that genes rotated 'higher' while forcing host genomes into a lower angle. |
Still, Fig 2.4.1 only shows how genes or DNA distribute over time when mapped on a diagram of this type. The angles appear to change because the DNA does. Yet if genes really do try to rotate to higher angles, there must be some "force" driving them to do so. True, that force is natural selection, but in a Fisher equation it is the pressure (wi - ![]() ) that drives the value D xi to increase. So how would selection drive D q i to increase in the new formulation?
) that drives the value D xi to increase. So how would selection drive D q i to increase in the new formulation?
Well, the equation is not fully derived yet, but to see how it works we must set some "goal" that all genes try to achieve. In standard theory the gene seeks maximum probability Pi of survival in the next generation. Take distribution of any gene as Di, and fitness of a host as Fi. The gene has a probability of existing of Pi = Di Fi, with maximum of Pi = 1 (when Di =1 and Fi = 1). This can be written (in standard theory) as;
Pi = xiwi
The new equations, though, would involve two new terms; e i, (the exact copy), and wG, (the fitness of the organism). The relationship of these new terms to wi and xi is not known. However, it is likely that that genes at high e i (highly conserved genes) tend to spread anyway, regardless of which host genome they happen to be in. Using this principle, we can approximate the new equation of Pi to be something like;
Pi = xi (wG + wie i2)/(e i2 + 1), or in angle notation;
Pi = xi (wG cos2 q i + wi sin2 q i)
Note that when e i (viz. q i) is low, xi must be inside a fit genome in order to propagate. Yet when e i is high, the gene relies on its inherent fitness. And strange as this equation appears, it fully conserves standard theory. For the condition wG = wi for any e i, or for e i = 0, the equation will revert to Pi = xiwi. (Note that cos2q i + sin2q i = 1.)
However, now we have Di and Pi, we can obtain Fi by dividing Pi/Di. Note that Pi has a "real" (scalar) value, but once this is divided by the coordinate D (xi, q i) this will result in a complex form of Fi, so we get;
Pi = xi (wG cos2 q i + wi sin2 q i)
Di = xi (cos q i + j sin q i) or, Di = (xi, q i)
Dividing Pi/Di gives;
Fi » wG cos q i - j wi sin q i
Note that Fi is approximate. (Following division there is an extra term in Fi that mostly reduces to 0, but might concern "past" or "future" events.) Again though, for the condition wG = wi or q i = 0, then Pi = xiwi. Or multiplying complex Fi by the complex Di will also give Pi = xiwi (the 'j' terms cancel) regardless of the value of q i (with some adjustments). So again, standard theory is conserved throughout.
Still, the equation is interesting. The first term shows that fitness of the organism, wG, only acts on the real component of selection (wG cosq i is "real"). This infers that while organisms can evolve new designs by natural selection, they carry perfected designs into the next generation without selecting them out! This is the second term (with j = Ö -1). All genes were first selected in real genomes, but in the past (-ve sign on j). The deeper in the past (as q i >> 0O) the further the chance of selection is rotated away from the effects of modern events.
This is why genes 'want' to rotate to higher angles. They are trying to avoid selection! Selection is costly, for genes and nature. If a gene is already perfected in function, it is inefficient to re-design it by selection each time. It took billions of years to perfect the eukaryotic cell, and hundreds of millions of years to evolve large animals. Yet an intelligent being can evolve in a few million years by reincorporating earlier designs perfected over billions of years past. 'Selfish' gene theory has said that the organism is a way for genes to spread. The new formulation shows how it works. Nature conserves perfected designs by its own processes. But when humans model those processes with the mathematical tools available, it appears as though genes try to avoid selection by rotating deeper into an imaginary plane.
2.4.4 The Fall of Fitness
One of the conditions of the Fisher equation is that mean fitness can only rise as xi spreads. But in life, this is often violated. Suppose that a genome G1, consisted of two genes, xi, yi at loci X, Y. Suppose that gene xi could double the total individuals in an area by splitting yi into two new genes t i and y i, then evolving G1 into two new genomes G2 and G3. Suppose now G1, G2, G3 each have 1,000 copies. We get;
G1(xi, yi) ® [G2(xi, t i) + G3(xi, y i)] (For this case count the copies.)
Here xi has doubled but yi has decreased. Plus if G1 has gone extinct, its fitness decreased despite that xi has increased. So fitness fell, but the condition wi = wG of the Fisher equation was violated, by the case that;
wxi > wG1 but w yi £ w G1 (Again, just count copies.)
If anything, one suspects that rather than sum q G over thousands of genes and billions of bp, one might assume that for a haploid q G » 45O, and a diploid q G » 0O. (When a new form of reproduction evolves, q G falls slightly. Evolution of sex was the 'great q G crash' from 45O to 0O, dwarfing all other decreases in q G.)
Suppose though, that a gene maximizes spread if it replicates in a genome at an effective 'angle' of 45O. This will occur at wG = wie i. Then for genes at q i < 45O, the gene can afford a lower host fitness, wG < 1, as this helps the gene increase effective angle. For conserved genes where q i > 45O the gene could afford a lower wi to get a 45O effective angle. It is not clear physically what this means, but it vaguely infers how sex works. Highly conserved genes can accept a high fitness penalty for other genes in the host, because they are going to spread anyway.
On the other hand, while the case wi > wG is hard to resolve, the case wi < wG (the gene damages host fitness) becomes clearer. Note, wG acts only on the real component of fitness. Broadly, any gene such as a rogue or parasite at q i < 45O is losing copy at each reproduction at a faster rate than average. (A 102 bp long fragment that is mutating at m i = 10-4 will destroy its copy in 106 reproductions.) The best strategy for such a gene is to "slow" its rate of reproduction, by damaging its host's fitness, at roughly wG µ e i. (At m i = 10-4 then the gene obtains equivalent copy of m at wG = 0.37. The figures are not researched.) Note too that the equation of complex fitness is;
Fi = wG cos q i - j wi sin q i
Lowering wG lowers the "real" part of the equation, so it pushes effective 'angle' of complex fitness higher. As a real process, rogue DNA damages host fitness because that is how it acts. But in the equation, the DNA is trying to increase its effective angle, hence its survivability, by rotating itself further away from the plane of real selection.
Generally, the gene, being "selfish", tries to manipulate a genome to its advantage, but the strategy will depend on the (wi, q i) of the gene. A rogue gene with a low (wi, q i) tries to replicate inside a strong genome with a high q G, despite that rogue genes might try to lower wG of the host. (A low angle genome, like in sexual organisms, can alter rapidly, so it might quickly find a way to throw out the rogue gene.) Yet a very strong gene will, paradoxically, want to see life populated by highly variable (but low angle) genomes, so the strong gene can spread within a huge variety of types. (It is like the computer industry. If you make a part like the CPU needed in all computers, then the larger the variety of low cost computers built, the more parts you can sell.)
2.4.5 The Ongoing Debate
In summary, how is it that effects claimed here to be a major factor in evolution, do not appear in the math of standard theory?
Well, the math of standard theory is explicit. It is describing a well-understood physical process, in that a gene that is fit is also increasing its frequency in a population, say, from 1% to 99% distributed, relative to a rival. Moreover, the gene that is fit, spreading this way, is also contained "within" the equation modeling the process occurring. (The gene that is spreading, is the same gene that the equation is describing.) However, when a favored gene is spreading, say 1% to 99% distributed, other genes in the genome are also spreading, even though, perplexingly, they might be 100% distributed already for that population. The difference is that the gene causing the spreading, the "action" gene, was altered from an earlier sequence to gain the fitness to spread. Yet the genes that spread anyway, that were already distributed 100%, are now carried along by the "action" gene into a new adaptation, but are not themselves forced to alter their own sequence to adapt. These genes, able to adapt into new varieties without themselves being forced to alter, gain slight fitness over genes forced to bear the cost of change.
To model this process, requires capturing the effects of fitness from the perspective of any gene in the genome, not just the "action" gene. This is done using a second quality of gene distribution; the "exact copy" of a gene, here called e i. Genes that survived unaltered for billions of reproductions, or adapted into a huge variety of types at no alteration to their sequence are versatile designs, that inherently end up widely copied. And organisms that adapt proven genetic designs (by reshuffling existing genes, rather than evolving new ones) ultimately adapt at lower total cost of change. So although e i is the copy fidelity of a gene over the history of life, it approximates the cost and directionality of change.
Yet, using e i must conserve the equations of standard theory where these are correct. This is done by adding e i to xi as a complex sum, so normalized distribution Di, becomes Di = xi(1 + je i)/Ö (e i2 + 1). This form conserves standard theory (say, by setting e i = 0). Still, manipulating this further provides a new equation, showing how wi (gene fitness) relates to wG, (fitness of the host genome in which the gene is resident). This is;
Fi = (wG - jwie i)/Ö (e i2 + 1), or in angle notation;
Fi = wG cos q i - j wi sin q i
This equation is incomplete. There are missing terms, and it does not show angle, q G, of the host genome (which might differ between diploid to haploid organisms). The equation also does not show the time variant conditions, or effective angle for Fi for a gene to maximize propagation. (Though one suspects it is 45O.) Even so, the equation does confirm how life works! Succinctly, it shows that fitness, wG, of the host genome acts on the "real" part of the equation, so as is suspected, it is the organism (not the gene) that is selected at each fitness event.
Genes reproduce physically, inside organisms. And they pass on to offspring physically, like passing a baton in a relay. Yet genes still only reproduce information. In the famous polymerase chain reaction (PCR) humans provide the chemical ingredients. It is the "information" in the DNA snippet, not the chemicals, that is multiplied millions of times. So, organisms play two roles in transmitting DNA. By physical reproduction they are a chemical relay station. By mutation and selection, they are a way to modify DNA information. DNA as molecules is copied as a "real" physical process, and change of sequence occurs at real physical events, even for events in the past. Even so, when modern organisms are selected for changes of allele frequencies, 99% of the stable sequences in those organisms are being copied in other organisms, in other times, over the biota of life. If one models this among a small population from which the gene has already radiated, it should show as 'imaginary' selection in a correctly formulated equation.
Yet if this equation is correct, it means that any gene at any locus in the genome, tries to increase not just its distribution fitness, xi, but its total fitness, xi(1 + je i)/Ö (e i2 + 1), where e i is the "exact copy" of the gene. When a gene first comes into existence, at e i = 0, the gene relies on the fitness of its host, wG, to spread. Here, wG = wi for that gene, which applies as in standard theory. But as the gene matures and radiates into many types, it will become less dependent on its host to avoid sequence death. Broadly, as e i increases the gene sequence radiates out from the point of origin of the sequence much like a wave, through millions of descendant reproductions. (When e i = 0, the gene is like a particle. When e i = ¥ , it is like a wave.) It has not yet been modeled, but it is hoped that some fast mutating DNA will exhibit this wave-like effect as a concerted synchronism across physically separate organisms.
Modern evolutionary theory has become divided between so-called gene-centric or reductionist models, focused on genes and equations, and a more holistic, observational approach. The assertions of this chapter seem to take the division to an extreme. Just when the reductionist school is conceding that genes might also be cooperative or parliamentary, this chapter argues why DNA is consistently selfish. Genes might cooperate to spread in unison, but each gene also competes to preserve its own copy unaltered, and force other genes in the genome to bear the cost of change. Just that genes compete for spread over tens of generations, but compete for exactness of copy over millions of generations, and this difference of scale is hard to model. This is the second contention. All the processes of life are real physical events at the instant when they occur. But within equations, humans try to capture events from billions of years past into single events of the present. Within this restriction equations will show strange effects, such as genes radiating like waves of information, rather than processes normally associated with life.
Even so, the math explained here is more a notational argument than proven equations, and no one equation anyway will ever fully capture the vast processes of life. Yet incomplete as it is, the argument here can still challenge existing models of how large-scale evolution works, or how genes and organisms do interact. Also, despite the reductionist approach inherent to equations, there is a cautious optimism. Even from a model of gene selfishness, these equations illuminate the one result that everybody suspected was the case all along. Evolution of complex new creatures, or complex new adaptations such as thought and emotion, will take more than just a few changes in allele frequencies. It is the combined effects of all evolution, accumulating over the history of life.
Return to EVOLUTION
Return to Theory of Options